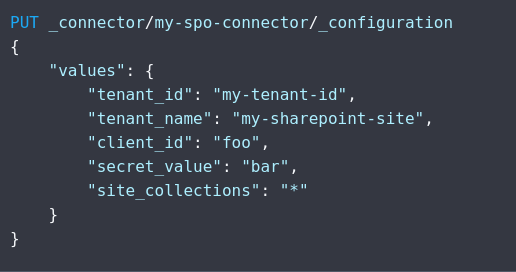
Opdaterer adgangskoden til en Connector til en database i Elastic via API. Mange organisationer har systemer som opsatere system konti og sætter nye koder på eksterne systemer. På den måde er det nemmere at sikere brugere og koder mod misbrug og samtidig ikke en byrde der skal huskes at gøres men kan ske automatisk.
Håndtering af mapnings fejl i Logstash
Det er ikke altid lige let at holde styr på mapningen i Elasticsearch. Specielt ikke hvis du får logs ind som ikke er i ECS format.
Ofte er der lige et eller andet som har ændret sig. Eller en eller anden servere sender pludselig noget som ikke var forventet.
Det som der oftest er fejlen er at feltet ikke er af samme type som det data der kommer. Det kan være at feltet er en integer og der kommer en streng eller måske en float. Dette vil så give en fejl som du kan se i Logstash loggen og du kan derfra se hvad der er problemer og kan tage stilling til om det er noget der skal fikses i Logstash med f.eks. en mutate. Du kan også forsøge at få det rettet ved kilden, så data der kommer er i det rigtige format.
Men det du skal tage stilling til længe før der kommer fejl er om du vil være sikker på at du ikke mister logs. I så fald kan du hvis du benytter Elasticsearch som output i din pipeline, aktivere Dead letter queue (DLQ). Dette skal gøre i Logstash konfigurations filen, ved at indsætte
dead_letter_queue.enable: trueHusk at genstarte Logstash før det træder i kraft.
Når du har gjort dette vil Logstash lave en kø for hver pipeline, hvor den gemmer dokumenter som fejler med en 400 eller 404 når den forsøget at sætte dem ind i Elasticsearch.
Loggen kan du så bruge i en ny pipeline hvor du benytter dead_letter_queue som input og derfra enten kan smide det i konsollen eller parse det og få det ind i Elasticsearch med den rigtige mapping.
Det er så smart at køen ikke automatisk bliver slettet. Så du har mulighed for at køre den flere gange. Når du så har fået de manglende logs på plads, kan du slette køen manuelt.
Du kan læse mere om det på Elastics hjemmeside her.
Relaterede indlæg