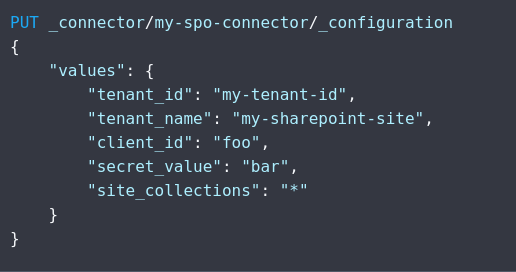
Opdaterer adgangskoden til en Connector til en database i Elastic via API. Mange organisationer har systemer som opsatere system konti og sætter nye koder på eksterne systemer. På den måde er det nemmere at sikere brugere og koder mod misbrug og samtidig ikke en byrde der skal huskes at gøres men kan ske automatisk.
Hvordan navngives data streams i Elasticsearch?
I Elasticsearch navngives data streams på nogle grundlæggende regler og best practice, som er defineret af Elasticsearch selv.
Her er en forklaring på, hvordan disse navne typisk dannes og bruges:
Data stream navngivning
Data stream navne i Elasticsearch genereres ved at kombinere tre dele:
- Type:
Beskriver den generelle type data (f.eks. “logs” eller “metrics”) - Dataset:
Beskriver den specifikke type data og dens struktur - Namespace:
En brugerdefineret gruppering
Disse tre dele kombineres med bindestreger for at danne data stream navnet:
{type}-{dataset}-{namespace}
For eksempel kunne et data stream navn være “logs-apache.access-production”
Hvert dokument i en data stream skal indeholde felterne data_stream.type, data_stream.dataset og data_stream.namespace.
Indeks navngivning
Indekserne, der bruges af datastreams i Elasticsearch, har følgende navngivningsformat:
.ds-<data-stream>-<yyyy.MM.dd>-<generation>
Her er en forklaring af de enkelte dele:
- “.ds-” er præfikset, der indikerer, at det er en datastream-indeks
- <data-stream> er navnet på datastreamen
- <yyyy.MM.dd> er datoen for indeksets oprettelse i år-måned-dag format
- <generation> er et sekscifret generationsnummer, der øges hver gang indekset ruller over
For eksempel kunne et indeksnavn se sådan ud:
.ds-logs-nginx.access-2024.12.17-000001
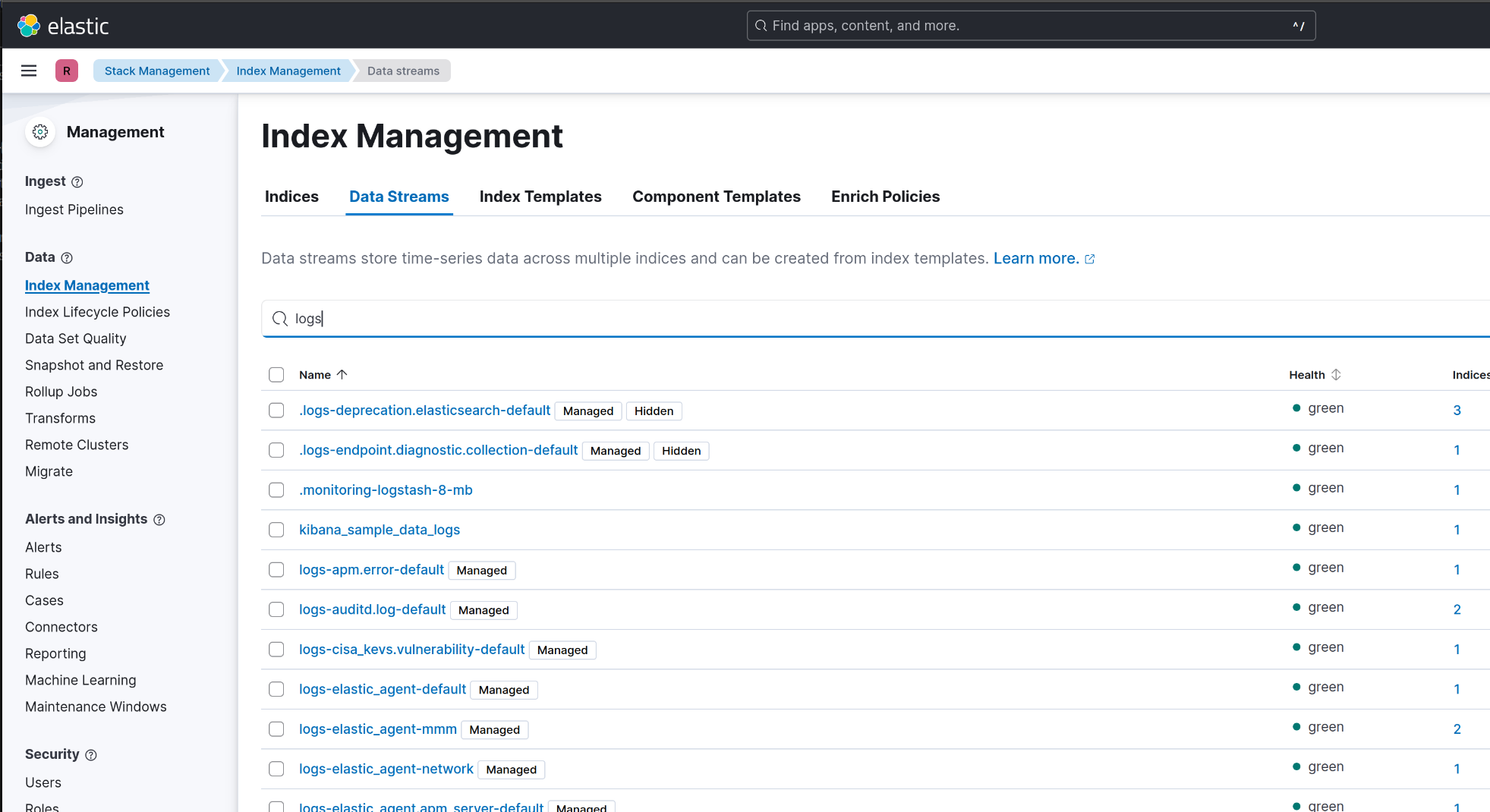
Husk at disse indekser er automatisk oprettede af dit data stream. De er derfor også normalt skjulte i Kibana.
Hvis du går ind på Stack Management -> Index Management i Kibana, vil du først se data stream indekser, når du har valgt at vise skjulte indekser (Include hidden indices).
Datoen i indeks navnet angiver ikke, at der oprettes et nyt indeks hver dag, men hvornår indeks blev oprettet.
Hvor tit der oprettes et nyt indeks, er afhængig af hvad der er definere i ILM på dit data stream.
Relaterede indlæg