Kibana har en måde at konfigurere og administrere dine Logstash-pipelines, så det er nemmere at se og konfigurere Logstash pipelines. Se her hvordan du gør.
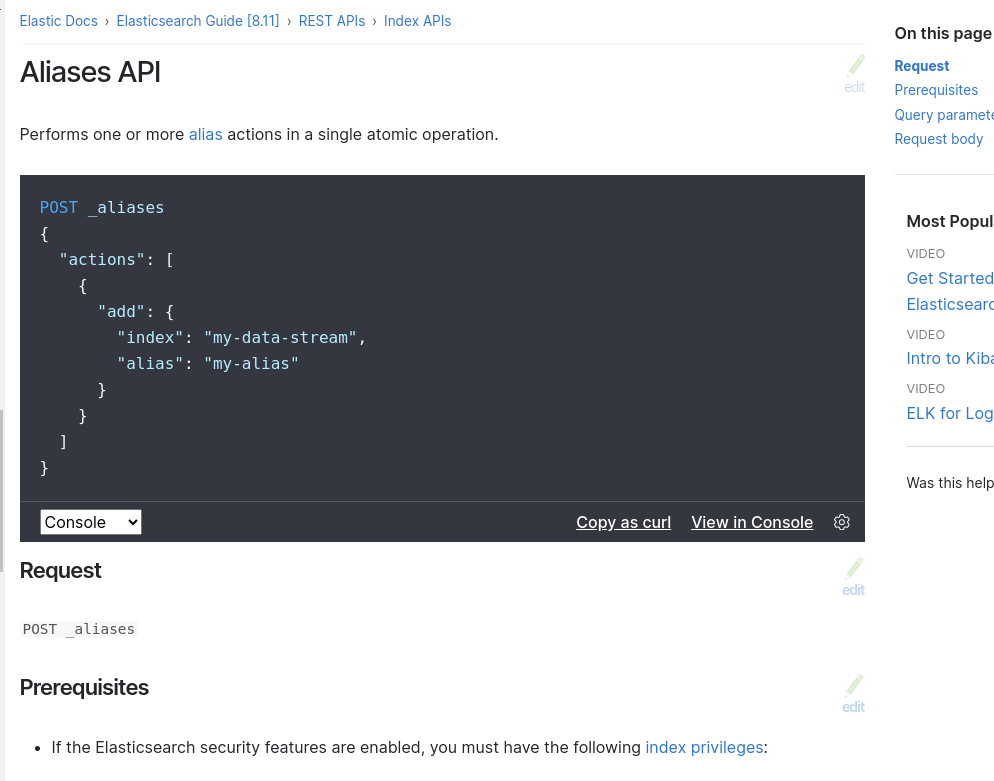
Hvilket index skrives der til når du bruger ILM i Elasticsearch?
Elasticsearch bruger en koncept kaldet „aliases‟ til at bestemme, hvilket index der skal benyttes. Et alias er en abstrakt navngivning, der peger på et eller flere indekser.
Når du arbejder med Elasticsearch, kan du oprette et alias og knytte det til et eller flere indekser. Når du udfører en søgning eller en skrivning, kan du henvise til aliaset i stedet for det specifikke indeksnavn. Elasticsearch vil derefter automatisk dirigere operationen til de indekser, der er knyttet til aliaset.
Aliases giver dig fleksibilitet til at styre, hvilket index der bliver benyttet, uden at du behøver at ændre dine applikationskoder eller konfigurationer. Du kan opdatere aliaset for at pege på forskellige indekser, fjerne eller tilføje indekser efter behov.
Du kan tilføje et allias ved at gøre føægede:
POST _aliases
{
"actions": [
"add": {
"index": "det-rigtige-index-navn",
"alias": "dit-alias-navn"
}
]
}
Jeg har tidligere skrevet et post om dette som du kan læse her.
Når vi benytter ILM i forbindlese med logs, vil der løbende blive flere indexes med alle logs, dem vil Elasticsearch give samme alias for at du kan bruge dem som „1‟ index. Men Elasticsearch skal stadig vide hvilket af disse indexes der skal sendes nye logs til.
Det gør den også ved hjælp af „aliases‟. Ved at definere på alias som det er et „write‟ index eller ikke.
POST _aliases
{
"actions": [
"add": {
"index": "det-rigtige-index-navn",
"alias": "dit-alias-navn",
"is_write_index": true
}
]
}
På samme måde sætte den „is_write_index‟ til false på de indexes som der ikke skal sendes logs til.
Du kan finde mere i Elasticsearch dokumentationen her.
Relaterede indlæg